1. 字符编码
只跟文本和字符串有关
由于计算机内部只是别二进制,但是用户在使用计算机的时候却可以看到各种语言字符,字符编码就是内部记录了人类字符与数字对应关系的数据
1.1 字符编码史
- 一家独大
1
2
3
4
5
6
7
| 计算机由美国发明,因此美国人为了能让计算机识别英文字符诞生了ASCII码表
特点:
只有英文字符与数字的一一对应关系
一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有的英文字符,目前只用到127个,剩下的为了后续发现新的语言
需要记住的是:
A-Z: 65-90
a-z: 97-122
|

- 群雄割据
1
2
3
4
5
6
7
8
9
| 中国:
GBK码:记录了英文中文与数字的对应关系
对于英文还是使用一个字节
中文使用了两个字节甚至更多字节,两个字节也不能够全部表示出所有的中文,需要生僻字需要更多位
日本:
shift_JIS码:记录了日文英文与数字的对应关系
韩国
Euc_kr码:记录了韩文英文与数字的对应关系
|
- 分久必合
1
2
3
4
5
6
7
8
| 为了能够实现不同国家之间的文本数据能够彼此无障碍交流需要对编码统一
unicode(万国码)出现了
特点:统一使用两个及以上字符记录字符与数字的对应关系
utf8(万国码的优化版)
英文还是用一个字节存储,中文使用三个字节或更多字节存储
现在默认使用的编码是uft8
|
1.2 编码操作
- 如何解决文件乱码
1
| 文件当初以什么编码编的,打开的时候就以什么编码解
|
- python解释器不同版本的编码差异
1
2
3
4
5
6
7
8
| python2.x内部使用的编码默认是ASCII
1.文件头
2.在python2中定义字符串前面需要加一个u
s = u'你'
python3.x内部使用utf8
|
- Pycharm定义文件模板内容
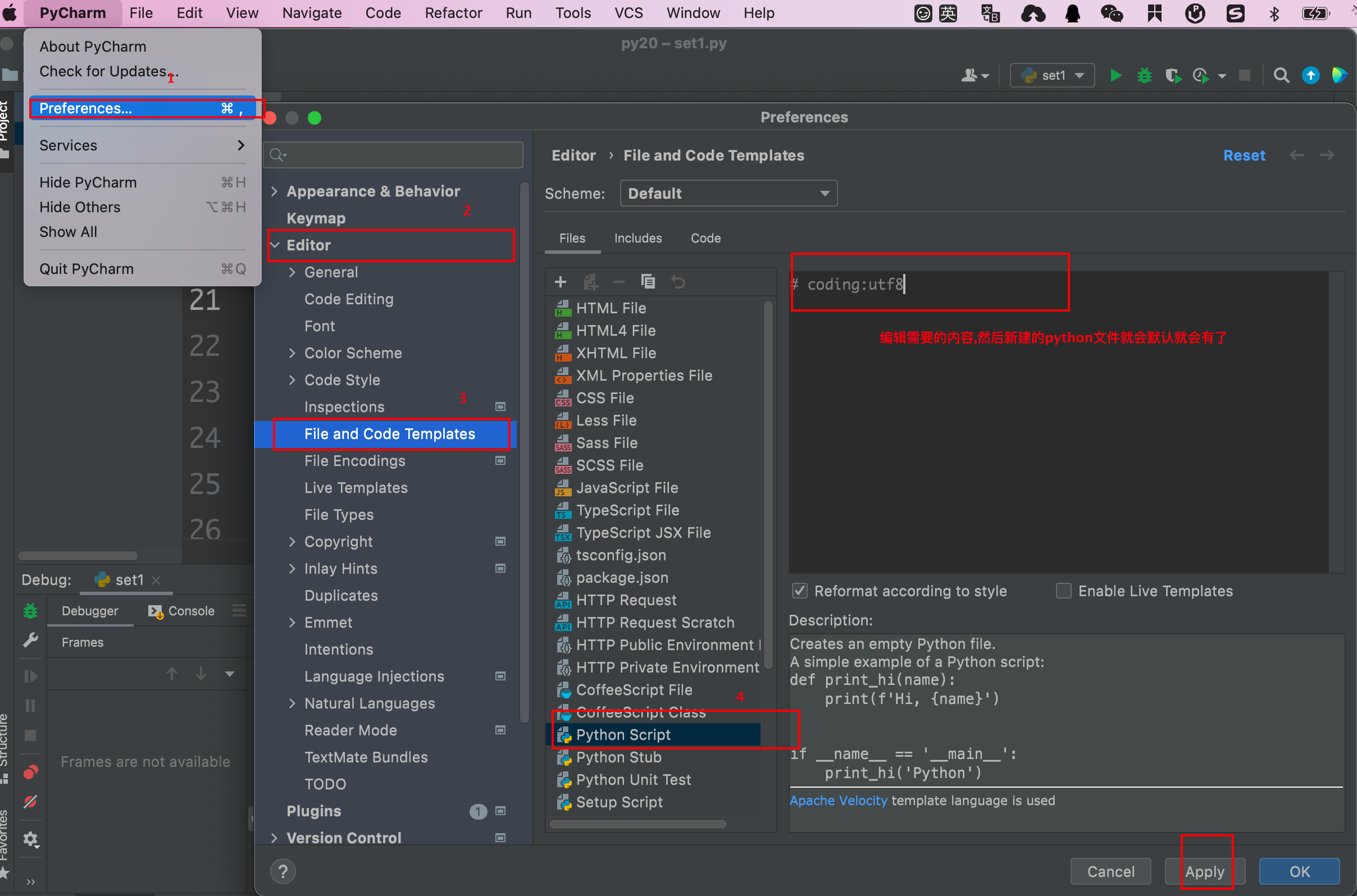
- 编码与解码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 编码
将人类能够读懂的字符按照指定的编码转换成数字
解码
将数字按照指定的编码转换成人类能够读懂的字符
eg:
s = '这是一段文字'
res = s.encode('utf8')
print(res, type(res))
res1 = res.decode('utf8')
print(res1)
|
2. 文件
2.1 文件操作
2.1.1 如何操作文件
1
2
3
4
| 关键字open()
1.open()打开文件
2.其他方法操作文件
3.关闭文件
|
2.1.2 路径斜杠
1
2
3
| 在路径中出现字母与斜杠的组合产生了特殊含义如何取消
在路径字符串前面加一个r
r'D:\py20\day08\a.txt'
|
2.1.3 操作文件
1
2
3
4
5
6
7
8
9
| 格式:
open(文件路径,读写模式,字符编码)
文件路径与读写模式是必须的
字符编码是可选的(有些模式需要编码)
eg:
res = open('a.txt', 'r', encoding='utf8')
print(res.read())
res.close()
|
2.1.4 with上下文管理
1
2
3
4
| 可以自动close()
eg:
with open(r'a.txt', 'r', encoding='utf8') as f1:
print(f1.read())
|
2.2 读写模式
2.2.1 只读模式 r
1
2
3
4
5
6
7
8
9
| 只能查看不能修改
with open(r'b.txt','r',encoding='utf8') as f1:
pass
with open(r'a.txt','r',encoding='utf8') as f1:
print(f1.read())
f1.write('123')
|
2.2.2 只写模式 w
1
2
3
4
5
6
7
8
9
|
with open(r'b.txt', 'w', encoding='utf8') as f2:
pass
with open(r'a.txt','w',encoding='utf8') as f1:
print(f1.read())
f1.write('123')
f1.write('\n123\n')
|
2.2.3 只追加模式 a
1
2
3
4
5
6
7
8
9
10
11
|
with open(r'c.txt', 'a', encoding='utf8') as f3:
pass
with open(r'a.txt', 'a', encoding='utf8') as f1:
f1.write('\nwoooooo')
f1.write('\nwoooooo')
print(f1.read())
|
3. debug代码调试
- 在代码右侧使用右键标记,空白处右键出现在Run下面有Debug运行
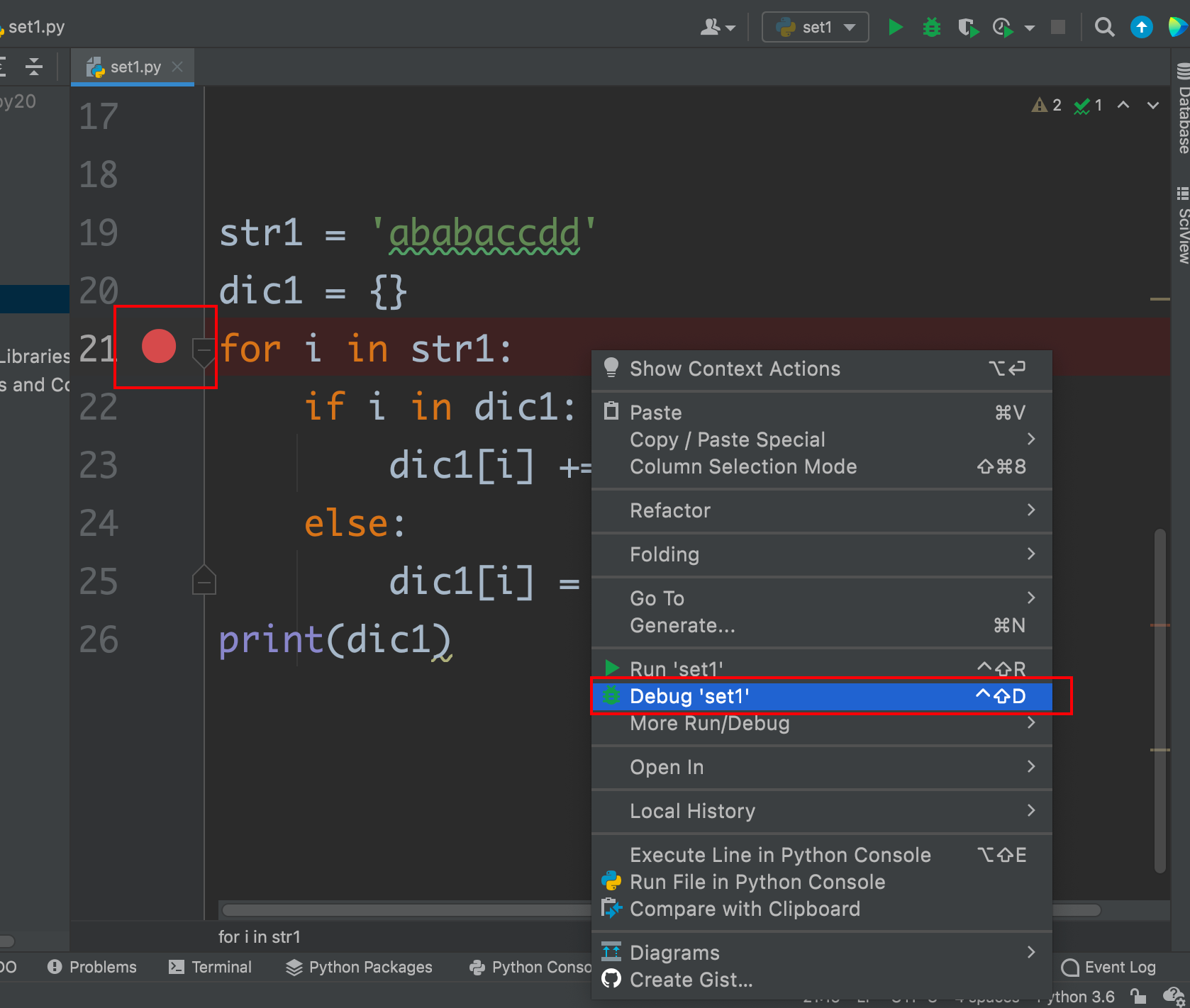
- debug运行的时候会一步步执行,并给出每一步的结果

- 停止debug
取消小点
