1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
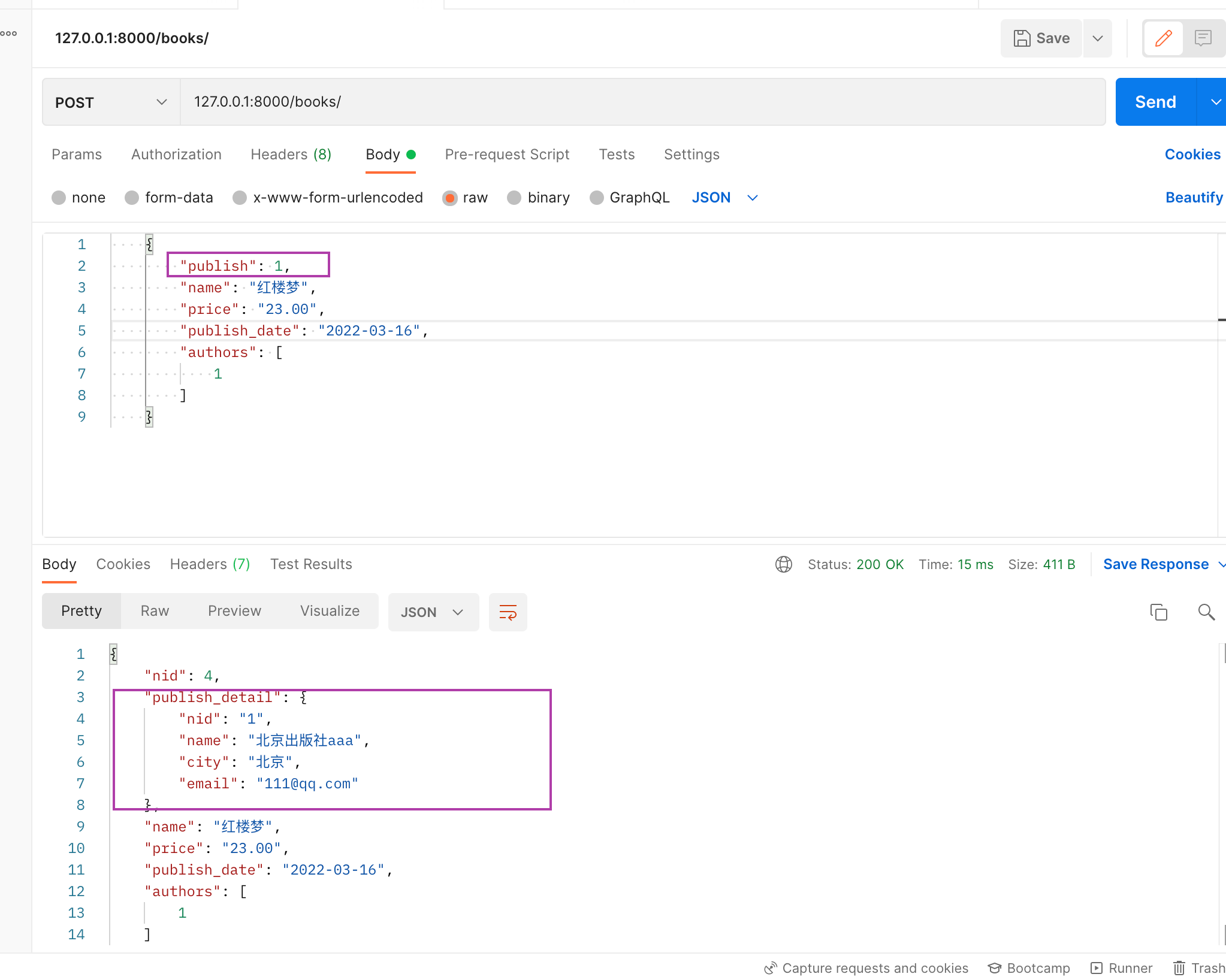
| '''
要求返回的字段内是字典
publish = {'name': 名字, 'city':城市, 'email': 邮箱}
'''
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.IntegerField()
publish = serializers.SerializerMethodField()
def get_publish(self, obj):
return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email}
'''
[
{
"name": "三国演义",
"price": 35,
"publish": {
"name": "北方出版社",
"city": "北京",
"email": "222@qq.com"
}
}
'''
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
return [{'id': author.nid, 'name': author.name, 'age': author.age} for author in obj.authors.all()]
'''
[
{
"name": "水浒传",
"price": 45,
"publish": {
"name": "南方出版社",
"city": "南京",
"email": "123@qq.com"
},
"authors": [
{
"id": 1,
"name": "xxx",
"age": 18
},
{
"id": 2,
"name": "yyy",
"age": 20
}
]
}
]
'''
|