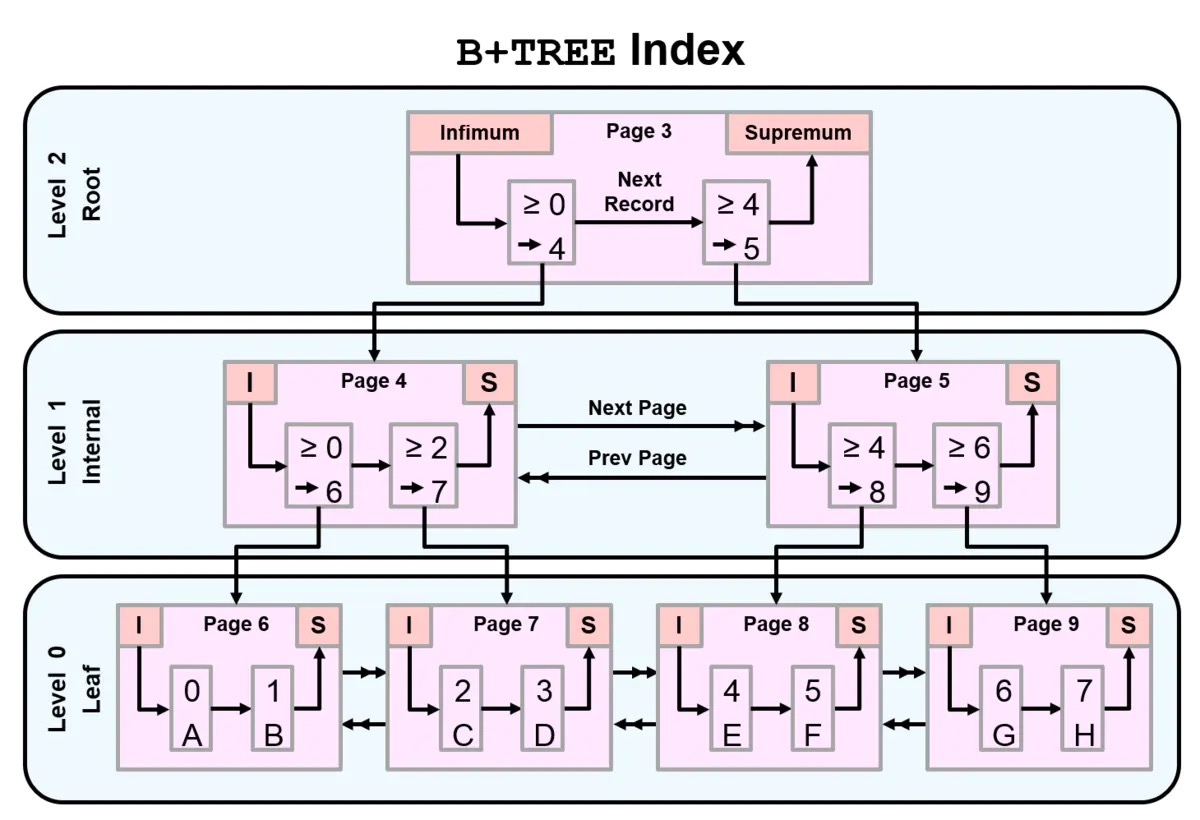
# type的级别如下,从上到下性能越好,至少优化到range以上 1. ALL: 全表扫描,不走索引 desc select * from t100w; # 没有条件能走索引的 没建立索引 建立索引不走 desc select * from t100w where k1='aa'; # 上面例子中创建的索引时针对k2列的,k1列并没有创建索引 desc select * from t100w where k2!='aaaa'; # 不等于的条件也是不走索引的 desc select * from t100w where k2 like '%xt%'; # 模糊查询时当%在前面时不走索引 或者not in也不走索引
2. index: 全索引扫描,将整个索引树全部扫描一遍才能达到效果 desc select k2 from t100w;
3. range: 索引范围扫描,扫描索引树的一部分 辅助索引 > < >= <= like in or # 这些语句会走范围扫描,尽量避免 in or 主键 != desc select * from world.city where id > 1000; desc select * from world.city where id != 1000; desc select * from world.city where countrycode like 'C%'; desc select * from world.city where countrycode in ('CHN','USA'); # 可以改写为下面的语句 desc select * from world.city where countrycode='CHN' union all select * from world.city where countrycode='USA'; # 此时可以看到type级别为ref 4. ref: 辅助索引等值查询 desc select * from world.city where countrycode='CHN';
5. eq_ref: 在多表连接查询时 on 的条件列时唯一索引或主键 desc select a.name,b.name,b.surfacearea from world.city as a join world.country as b on a.countrycode=b.code where a.population < 100;
6. const,system: 主键或唯一键等值查询 desc select * from world.city where id=10; 7. null: 查不到数据的时候
Extra额外的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# 当出现 using filesort 时说明索引设计不合理, 使用了文件排序 desc select * from world.city where countrycode='CHN' order by population;
# 没见索引之前 desc select * from world.city where countrycode='CHN' order by population limit 10;
# 建立联合索引 alter table world.city add index idx_co_po(countrycode,population); desc select * from world.city where countrycode='CHN' order by population limit 10;
结论: 1.当我们看到执行计划extra位置出现filesort,说明由文件排序出现 2.观察需要排序(ORDER BY,GROUP BY ,DISTINCT )的条件,有没有索引 3. 根据子句的执行顺序,去创建联合索引